


One of the most exciting announcements at Microsoft Ignite – alongside the unveiling of Azure Arc – is Azure Synapse. Synapse is set to transform how businesses to store, retrieve, and leverage data to drive business outcomes by enabling data from both the data warehouse and data lake to be managed and analyzed in tandem.
Currently, organizations must maintain their data lake and a data warehouse separately. A data warehouse can only store structured data. This makes it easy to organize and leverage particular types of data but presents a problem for large, unstructured datasets. In contrast, a data lake can store any type of data, regardless of structure.
Both warehouses and lakes have their uses, and most organizations use both for various purposes. But getting the two to work together to unify all organizational data and create a unified vision of the product, customer, processes, employees, and business health has eluded companies – until now.
Enter Azure Synapse. Dubbed “the next evolution of Azure SQL Data Warehouse,” Synapse brings the data warehouse and data lake together to let organizations query data using provisioned or serverless on-demand resources. From ingestion to management, Synapse creates a unified user experience that enables enterprises to leverage the full capabilities of Big Data and machine learning.
To accomplish this, Synapse taps into Power BI and Azure Machine Learning, alongside a plethora of third-party solutions like Apache Spark, Databricks, and Accenture.
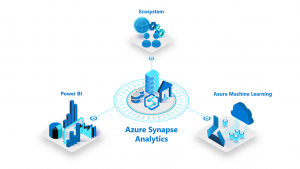
What Azure Synapse Means for the Enterprise
There are many implications of Azure Synapse for enterprises.
The goal of Synapse is to let users work with and manage all of their data from a “single source of truth,” regardless of where that data is stored. This enables businesses to use existing workloads in production with Synapse, thereby automatically getting all of the benefits of Synapse automatically. As Rohan Kumar, Microsoft CVP of Azure Data says, “Businesses can put their data to work much more quickly, productively, and securely, pulling together insights from all data sources, data warehouses, and big data analytics systems.”
The entire data warehouse infrastructure has been augmented with new features to go toe-to-toe with other cloud warehouse platforms. This includes the ability to accommodate workloads through both explicitly provisioned and on-demand, serverless infrastructure.
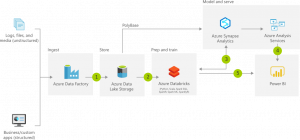
Another key feature is the Apache Spark and Azure Data Lake Storage integration, which facilitates the unification of data lake workloads with the data warehouse.
All of this is brought together in Azure Synapse Studio, a unified web user interface. Synapse Studio lets users accommodate data prep and management for both data warehouse and data lake workloads, along with Azure Data Factory.
At Microsoft Ignite, when Synapse was benchmarked against Google’s BigQuery, Synapse ran a query over a petabyte of data 75% faster than BigQuery. Additionally, Synapse was shown to be three times faster than Amazon’s Red Shift. And unlike BigQuery or Red Shift, Synapse can handle thousands of users concurrently.
Azure Synapse boasts several benefits for engineers. Developers will no longer need to copy terabytes of data from disparate sources and systems – a common pain point for enterprises that leverage both data lakes and warehouses. Along with time savings, this will enable engineers to integrate data sources with virtually any data analytics engine of their choosing.
Have questions about how to implement and benefit from Azure Synapse at your organization? Contact the Azure Cloud experts at Hanu today. We’re happy to answer any questions you might have. We will also provide a FREE assessment of your entire IT infrastructure and data estate.
